*.csv

The e-commerce market heavily relies on e-coupons, and their digital nature presents challenges in establishing a secure e-coupon infrastructure, which incurs maintenance costs. To address this, we explore using public blockchains for the e-coupon system, providing a highly reliable decentralized infrastructure with no maintenance costs. Storing coupon information on a blockchain ensures tamper resistance and protection against double redemption. However, using public blockchains shifts gas cost responsibility to users, potentially impacting user experience if not managed carefully.
- Categories:
 125 Views
125 Views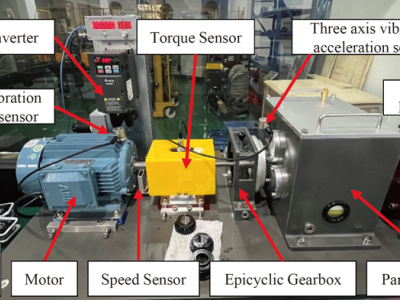
The gearbox is a critical component of electromechanical systems. The occurrence of multiple faults can significantly impact system accuracy and service life. The vibration signal of the gearbox is an effective indicator of its operational status and fault information. However, gearboxes in real industrial settings often operate under variable working conditions, such as varying speeds and loads. It is a significant and challenging research area to complete the gearbox fault diagnosis procedure under varying operating conditions using vibration signals.
- Categories:
397 Views
DataSet used in learning process of the traditional technique's operation, considering different devices and scenarios, perform the commutation through Pure ALOHA protocol, and make the device to operate with the best possible configuration.The control of energy consumption is essential for the operation of battery-operated systems, such as those used in IoT networks and sensors. The algorithms commonly employed for this purpose involve optimization functions with considerable complexity and rigorous control of the test environment.
- Categories:
185 Views
This dataset accompanies a research paper on leveraging Machine Learning (ML) techniques for regression to predict the optimum DC bias in direct current in optical orthogonal frequency division multiplexing (DCO-OFDM). The dataset comprises a set of features to facilitate the prediction of the required DC bias to mitigate the impact of clipping distortion at the transmitter. MATLAB software was utilized for modelling the DCO-OFDM transmission and generating the research dataset.
- Categories:
49 Views
The Comprehensive Hindi Hostile Post Detection Dataset (CM-HTHPD) is collection of Twitter posts written in the Hindi language, focusing on various forms of hostile content. The dataset was gathered using the Twitter Developer API and subsequently annotated manually with sentiment labels using the Label Studio platform. The dataset is primarily aimed at facilitating research and analysis in the domain of hostile content detection and sentiment analysis in Hindi-language social media discourse. The size of the dataset is approx 8300.
- Categories:
24 Views
16.00
Normal
0
false
false
false
EN-GB
X-NONE
X-NONE
- Categories:
148 Views
Nowadays, the high cost of customer acquisition makes telecom operators encounter the “ceiling”, and even fall into the dilemma of customer acquisition. As market saturation increases, telecom operators need to solve the problem of increasing subscriber stickiness and prolonging subscriber life cycle. Therefore, it is crucial to analyse and predict the churn of telecom users. The dataset is ”Telecom Operator Customer Dataset”. The dataset obtained from the official Kaggle competition website in this study, which comprised 21 fields.
- Categories:
234 Views
The dataset crafted for this study is intentionally designed to encapsulate instances of cyberbullying across three distinct languages: Urdu, Roman Urdu, and English. This strategic selection aims to mirror the linguistic variations that are prevalent in social media dialogues among Urdu-speaking communities globally. Further, it undergoes meticulous annotation to encapsulate the diverse linguistic nuances characteristic of these languages. This process includes integrating critical aspects of cyberbullying, such as aggression, repetition, and intent to harm.
- Categories:
141 Views
This data repository comprises three distinct datasets tailored for different predictive modeling tasks. The first dataset is a synthetic dataset designed to simulate multivariate time series patterns, incorporating both linear and non-linear dependencies among input and target features. The second dataset, the Beijing Air Quality PM2.5 dataset, consists of PM2.5 measurements alongside meteorological data like temperature, humidity, and wind speed, with the objective of predicting PM2.5 concentrations.
- Categories:
197 Views
We utilized Digital Ocean's cloud service, setting up three Linux virtual machines, each with 1vCPU, 1GB of memory, and a 10GB disk. The architecture included an API gateway for routing requests to a stateless application service backed by a database for storing application data. The application operates the service under a fluctuating workload generated by a load-testing script to simulate real-world usage scenarios. The target source or the application service is integrated with Prometheus, a monitoring tool for gathering system metrics.
- Categories:
182 Views