convolutional neural networks

The Baseline set described in the IEEE article (https://ieeexplore.ieee.org/document/10077565) as Baseline_set contains 1442450 rows, where the number of rows varied between 15395 and 197542 for the 16 subjects; the average per subject being 69095 rows. The data set is filtered and standardized as described in III.C in the submission . The other data sets used in the article are derived from Baseline set.
- Categories:
 687 Views
687 Views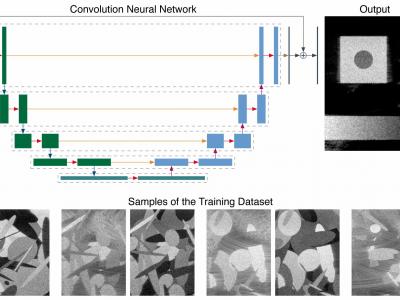
This repository contains the data related to the paper “CNN-Based Image Reconstruction Method for Ultrafast Ultrasound Imaging” (10.1109/TUFFC.2021.3131383). It contains multiple datasets used for training and testing, as well as the trained models and results (predictions and metrics). In particular, it contains a large-scale simulated training dataset composed of 31000 images for the three different imaging configuration considered (i.e., low quality, high quality, and ultrahigh quality).
- Categories:
2422 Views
Dementia classification from Magnetic Resonance Images by Machine Learning
- Categories:
371 Views
BTH Trucks in Aerial Images Dataset contains videos of 17 flights across two industrial harbors' parking spaces over two years.
- Categories:
1385 Views
This dataset contains the images used in the paper "Fine-tuning a pre-trained Convolutional Neural Network Model to translate American Sign Language in Real-time".
M. E. Morocho Cayamcela and W. Lim, "Fine-tuning a pre-trained Convolutional Neural Network Model to translate American Sign Language in Real-time," 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 2019, pp. 100-104.
- Categories:
1952 Views
Conveyor belts are the most widespread means of transportation for large quantities of materials in the mining sector. This dataset contains 388 images of structures with and without dirt buildup.
One can use this dataset for experimentation on classifying the dirt buildup.
- Categories:
928 Views
Since there is no image-based personality dataset, we used the ChaLearn dataset for creating a new dataset that met the characteristics we required for this work, i.e., selfie images where only one person appears and his face is visible, labeled with the person's apparent personality in the photo.
- Categories:
3207 Views
As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed. To achieve this goal, we introduced a large-sacle (~1.72M frames) traffic sign detection video dataset (CURE-TSD) which is among the most comprehensive datasets with controlled synthetic challenging conditions. The video sequences in the
- Categories:
4638 Views
As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed.
- Categories:
3519 Views
- Categories:
453 Views